
Ordered Systems Lab
Welcome! Our group aims to advance the principles and practice of building next-generation dependable systems that run on diverse computing platforms across the spectrum.

Research Interests
Our research spans broadly across operating systems, distributed systems, cloud computing, mobile systems, and ML infrastructure, while specializing in reliability,
fault tolerance, and performance. Our work combines systems building with deep insights to address real-world challenges facing modern systems and achieve ORDER.
Our research innovations cover:
- Foundation: Design formal reasoning techniques to ensure strong correctness guarantees in complex systems.
- Abstraction: Introduce new abstractions and interfaces to address fundamental gaps while avoiding ad-hoc designs.
- Analysis: Develop automated program analyses, data-driven methods, and ML techniques to better reason about system behavior.
- Runtime: Build robust runtime mechanisms to observe, mitigate, and recover from assorted issues while enabling self-adapting systems.
ORDER := {Observable, Reliable, Defensible, Efficient, Responsive}
News
- Jul 2026 LiteLib is accepted to NSDI '27! LiteLib provides lightweight replicas for stateful applications to prevent cascading and metastable failures.
- Jul 2026 BRAIN is accepted to NSDI '27! BRAIN is an end-to-end outage declaration system to tackle the next steps beyond failure detection in production cloud services.
- Jul 2026 OpGuard was nominated for the OSDI '26 best paper award!
- Mar 2026 OpGuard is accepted to OSDI '26! OpGuard introduces bitwise alignment for effectively debugging errors in production LLM training jobs.
- Dec 2025 Yuzhuo successfully defended his PhD thesis titled "Operating System Support for Reliable Software" and will join Google after graduation. Congratulations, Dr. Jing!
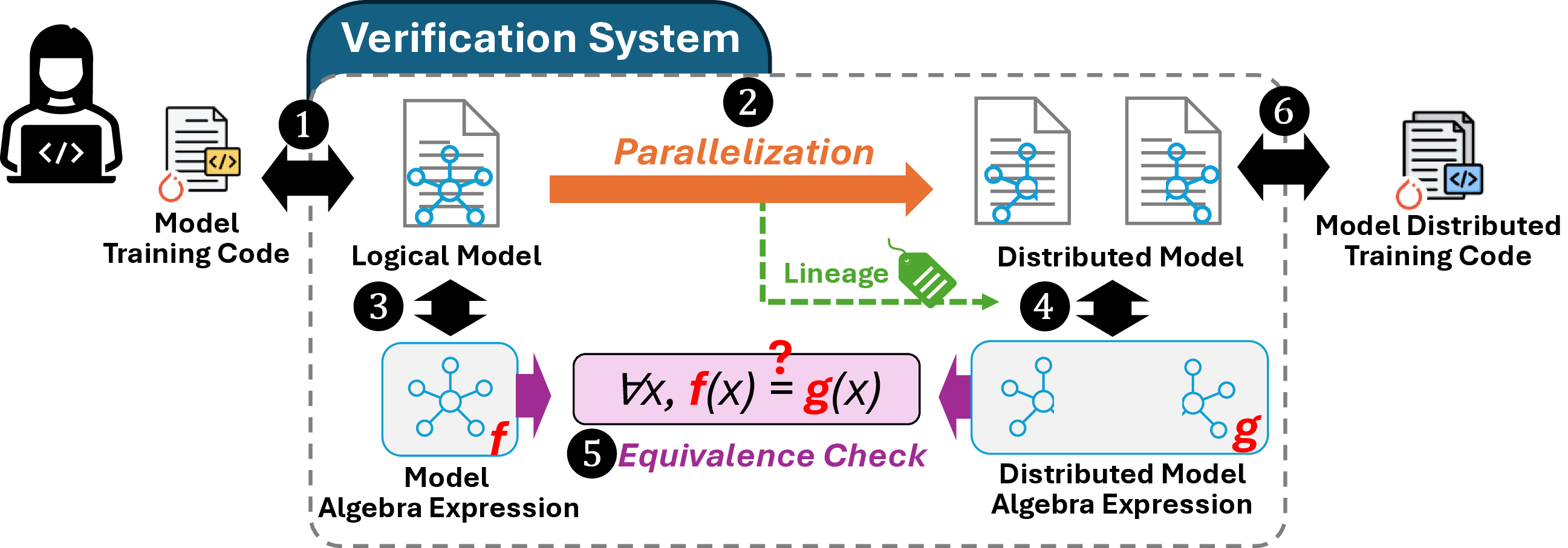
- Jul 2025 TrainVerify is accepted to SOSP '25! TrainVerify uses equivalence-based verification to provide strong correctness guarantess for the parallelization logic of distributed LLM training.
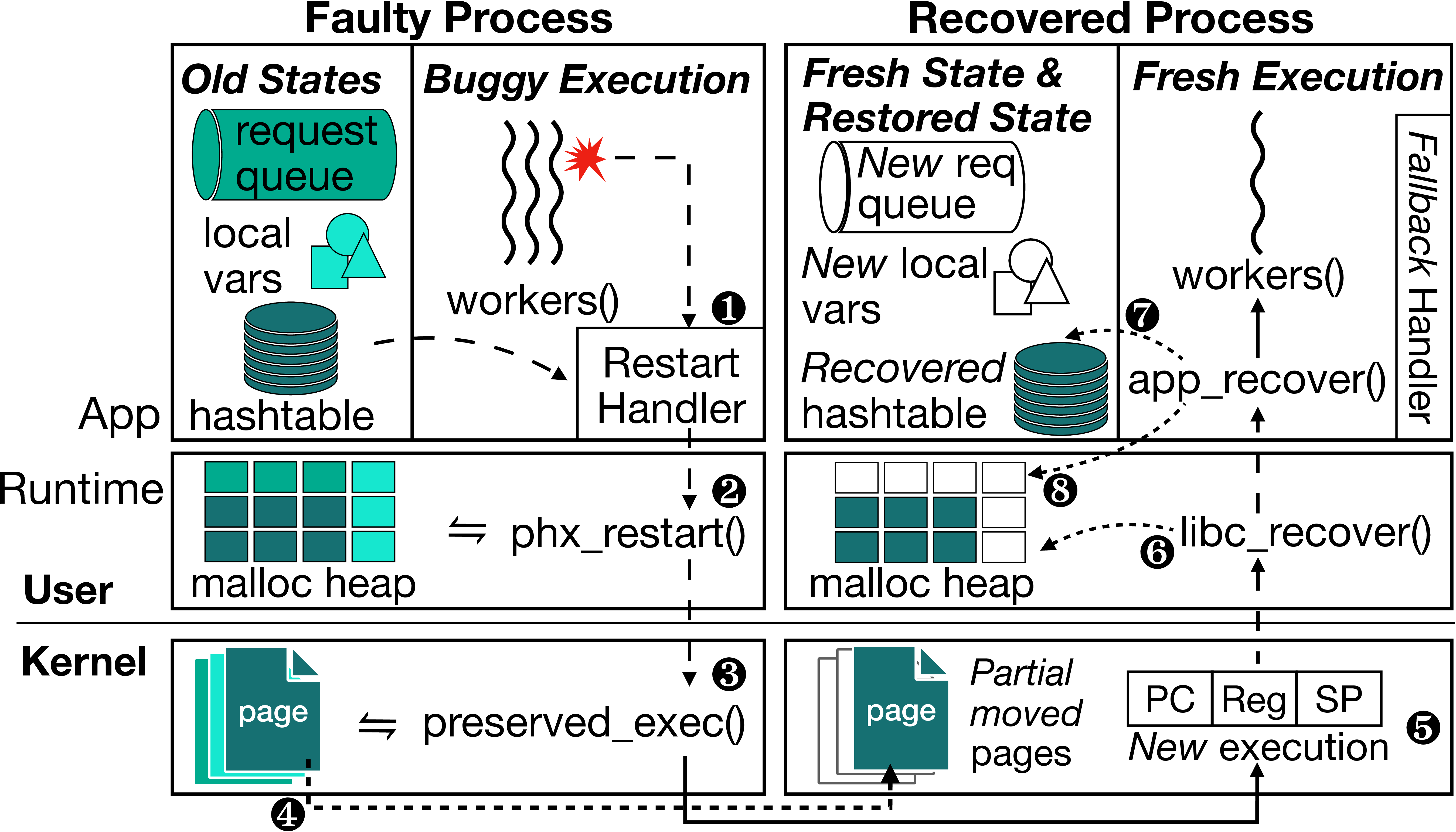
- Jul 2025 Phoenix is accepted to SOSP '25! Phoenix provides OS-level optimistic recovery and partial state preservation for high-availability software.
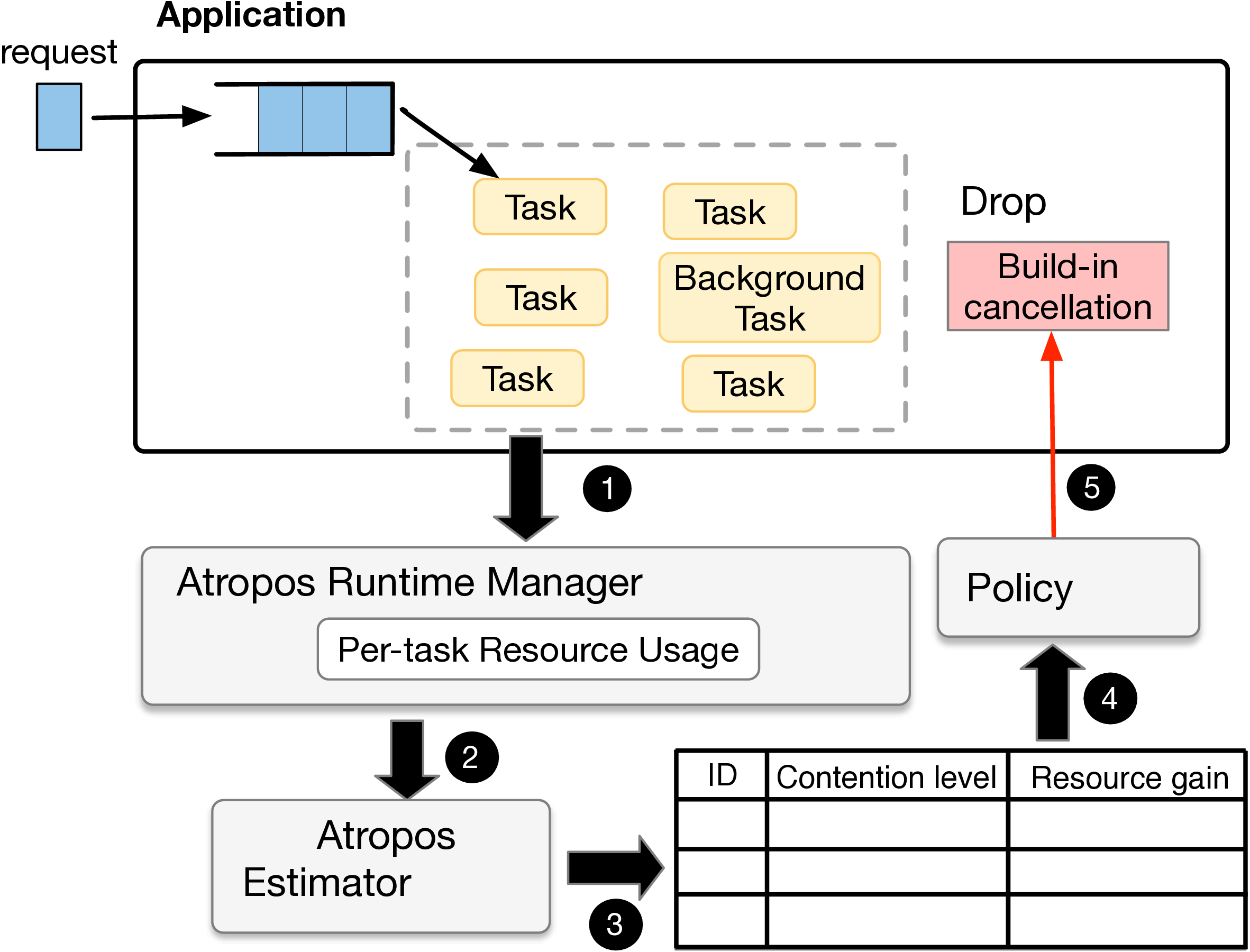
- Jul 2025 Atropos is accepted to SOSP '25! Atropos is an application overload control framework that uses targeted cancellation to maintain tight SLOs.
- Mar 2025 TrainCheck is accepted to OSDI '25! TrainCheck automatically infers invariants tailored for DL training and uses these invariants to proactively detect silent training errors.
Recent Projects

From the Blog
Updates on lab research, milestones, and practices.
Writing Posts for This Site
Blog entries are standard Jekyll posts. Create a markdown file under _posts/ with this naming pattern:
Read PostLaunching the OrderLab Blog
We have added a dedicated blog to the lab website to share technical updates in a faster, more narrative format than conference papers.
Read PostSponsors
We appreciate our sponsors for their funding and support, which made our research possible.




