Quick Start: TrainCheck Tutorial
In this tutorial, you will use TrainCheck to detect & diagnose the real‑world silent issue in PyTorch‑Forum‑84911: Obtaining abnormal changes in loss and accuracy, with invariants inferred from PyTorch’s official MNIST example. We’ll refer to this buggy pipeline simply as '84911'.
Estimated time: ~5 minutes (plus model/inference overhead)
Prerequisites
- A working TrainCheck installation
- efficientnet_pytorch and torchvision (install via pip3 install efficientnet_pytorch torchvision)
- A Linux machine with a CUDA‑enabled GPU
- 💡 Tip: If you don’t have a CUDA GPU, you can still run this tutorial on CPU—it’ll just take longer.
Background: What’s wrong with 84911?
The author attempts to finetune a pretrained EfficientNet_b0 model for image classification but notices that—even after many epochs—the training loss barely improves (x‑axis = epoch, y‑axis = loss):
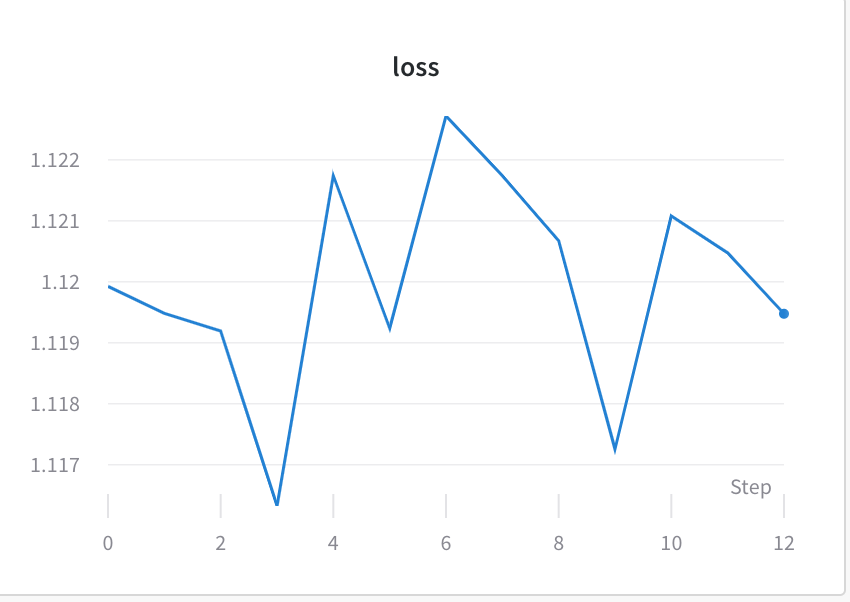
It appears from the plot that the model is still being trained, but somehow it is just not improving meaningfully. The original issue post discussed adjusting learning rate, and training for longer epochs. However, the issue remained unresolved.
We have diagnosed the root cause for you. You can look at it now or come at it yourself with the help of TrainCheck.
Click here to reveal the root cause.
The developer, for some reason, sets `requires_grad` to `False` for all parameters except for batch normalization layers, yet only initializes the optimizer with the final fully-connected layer. This freeze logic leaves virtually no trainable parameters. Since batch normalization layers still update their running mean/variance each forward pass, the loss/accuracy curves drift slightly instead of remaining flat—masking the lack of actual learning. Logging metrics only once per epoch further hides the anomalies, so the initialization bug only becomes apparent after several epochs have already run.
Detecting & Diagnosing 84911
We will infer invariants from the mnist.py, a very simple PyTorch-official pipeline that trains a 2-layer CNN on MNIST, to showcase TrainCheck's capability.
1. Download example scripts
cd ~
mkdir traincheck-tutorial && cd traincheck-tutorial
wget https://raw.githubusercontent.com/OrderLab/traincheck/main/docs/assets/code/mnist.py
wget https://raw.githubusercontent.com/OrderLab/traincheck/main/docs/assets/code/84911.py
💡 If the wget links above fail (e.g. due to branch changes or access issues), you can also download the files manually from: - mnist.py - 84911.py
2. Instrument & collect trace from mnist.py (~1 minute)
traincheck-collect \
--pyscript mnist.py \
--models-to-track model \
--output-dir traincheck_mnist_trace
This instruments torch and model in mnist.py, runs it with default arguments, and writes JSON trace files into traincheck_mnist_trace/ (≈ 1 minute). You’ll see the training logs and any benign PyTorch warnings on stdout.
3. Infer Invariants from mnist.py (~1-4 minutes)
We will infer invariants from the trace we just collected using the command below.
This will produce an invariants.json file (one JSON Line per invariant). Verify the count:The generated invariants capture API invocation order, event expectations, and input-output relationships. Since the trace comes from a single, simple script, some invariants may overfit—we’ll cover filtering in the next steps.
4. Check for silent issues in 84911.py with invariants (~5-10 minutes)
Note: For this quickstart, we do offline checking for simplicity.
# trace the buggy pipeline (~5 minutes)
traincheck-collect \
--pyscript 84911.py \
--models-to-track model_transfer \
--output-dir traincheck_84911_trace
# run the checker (~2–6 minutes)
traincheck-check \
--trace-folders traincheck_84911_trace \
--invariants invariants.json
The output of the traincheck-check command will contain this in the end:
Checking finished. 913 invariants checked
Total failed invariants: 25/913
Total passed invariants: 888/913 # number here includes both passed and not triggered invariants
Total invariants that are not triggered: 552/913
361 invariants were checked on 84911.py, and 25 got violated.
The checker writes the full results to a folder named traincheck_checker_results_<timestamp>, containing the results (failed.log, not_triggered.log, passed.log, depending if an invariant is violated, not checked at all, or checked and passed.), and a copy of invariants.json.
5. Detection & Diagnosis
Ready to play detective? 🔍 TrainCheck flagged 25 invariant violations right at the start of training—well before the fluctuating loss/accuracy pattern was observed. Let’s interpret the results first and then if you want to learn more.
1. Quick filter
- Event‑order invariants noise (20/25 failures):
- FunctionCoverRelation and FunctionLeadRelation invariants (basically specifying API invocation orders) overfit our single demo trace.
- Examples: strict ordering of torch.distributed.is_initialized (6 invariants violated but we are not even doing distributed training in 84911!) or torch.cuda.is_initialized (another 7 invariants violated but shouldn't matter at all for training).
- Ignore these.
2. Spot the real issues
- APIContainRelation invariant violations (5/25):
1. Optimizer.zero_grad did not reset .grad from non-zero to zero/None.
- Implies either no gradients were ever populated or zeroing silently failed.
2. Adadelta.step did not update .data of any parameters.
- Indicates the optimizer had no trainable parameters to touch.
🧩 Putting it all together: The optimizer wasn’t updating anything because… the parameters it received had requires_grad=False. Go to Background: What’s wrong in 84911? to see the full root cause confirmed and explained.
🙋 Click here to learn how to inspect the raw results
Open the `failed_*.log` file—TrainCheck writes each violated invariant as a standalone JSON object. For example:
{
"invariant": { … },
"check_passed": false,
"triggered": true,
"detection_time": 18343040207314524,
"detection_time_percentage": 0.1805434802294184,
"trace": [
{
"func_call_id": "...",
"meta_vars.step": 1,
"function": "torch.optim.optimizer.Optimizer.zero_grad",
…
}
...
]
}
{
"invariant": {
"relation": "APIContainRelation",
"params": [
{
"param_type": "APIParam",
"api_full_name": "torch.optim.optimizer.Optimizer.zero_grad"
},
{
"param_type": "VarTypeParam",
"var_type": "torch.nn.Parameter",
"attr_name": "grad",
"pre_value": "non_zero",
"post_value": null
}
],
"precondition": {
"parent_func_call_pre": {
"inverted": true,
"preconditions": [
{
"clauses": [
{
"type": "constant",
"prop_name": "meta_vars.step",
"additional_path": "None",
"prop_dtype": "int",
"values": [
0
]
}
]
},
{
"clauses": [
{
"type": "constant",
"prop_name": "meta_vars.stage",
"additional_path": "None",
"prop_dtype": "str",
"values": [
"testing",
"init"
]
}
]
}
]
}
},
"num_positive_examples": 20,
"num_negative_examples": 1
},
"check_passed": false,
"triggered": true,
"detection_time": 18343039144178123,
"detection_time_percentage": 0.16245728748900484,
"trace": [
{
"func_call_id": "3f7265b362c34725b412cf693ceea8f3_18343039144122325",
"thread_id": 140156043466560,
"process_id": 1263911,
"meta_vars.step": 1,
"type": "function_call (pre)",
"function": "torch.optim.optimizer.Optimizer.zero_grad",
"is_bound_method": true,
"obj_id": 140152527083248,
"args": {
"0": {
"torch.optim.adadelta.Adadelta": {}
}
},
"kwargs": {},
"time": 18343039144178123,
"return_values": NaN,
"var_name": NaN,
"var_type": NaN,
"mode": NaN,
"dump_loc": NaN,
"attributes._TRAINCHECK_data_ID": NaN,
"attributes.data": NaN,
"attributes.dtype": NaN,
"attributes.grad": NaN,
"attributes.grad_fn": NaN,
"attributes.is_cpu": NaN,
"attributes.is_cuda": NaN,
"attributes.is_ipu": NaN,
"attributes.is_leaf": NaN,
"attributes.is_meta": NaN,
"attributes.is_mkldnn": NaN,
"attributes.is_mps": NaN,
"attributes.is_mtia": NaN,
"attributes.is_nested": NaN,
"attributes.is_ort": NaN,
"attributes.is_quantized": NaN,
"attributes.is_sparse": NaN,
"attributes.is_sparse_csr": NaN,
"attributes.is_vulkan": NaN,
"attributes.is_xla": NaN,
"attributes.is_xpu": NaN,
"attributes.itemsize": NaN,
"attributes.name": NaN,
"attributes.nbytes": NaN,
"attributes.ndim": NaN,
"attributes.requires_grad": NaN,
"attributes.retains_grad": NaN,
"attributes.shape": NaN,
"attributes._TRAINCHECK_grad_ID": NaN,
"exception": NaN,
"exception_msg": NaN,
"proxy_obj_names": NaN
}
]
}
🎉 You just used TrainCheck to catch a real-world silent bug before it impacted training!