Overview
Currently, we have two main lines of investigations. One line is related to rethink availability and fault tolerance in cloud systems. The other is on defensive mobile operating systems to tolerate misbehaving apps.
Towards gray-tolerant cloud systems
Generating watchdogs to localize gray failure

In this work, we advocate that modern software needs intrinsic failure detectors that are tailored to individual systems and can detect anomalies within a process at finer granularity. We particularly advocate a notion of intrinsic software watchdogs and propose an abstraction for it. Among the different styles of watchdogs, we believe watchdogs that imitate the main program can provide the best combination of completeness, accuracy and localization for detecting gray failures.
We write a position paper on the watchdog abstraction and an early exploration for automatically generating mimic-type watchdogs. This paper is published at HotOS 2019.
Capturing observability to detect gray failures

In this work, we build on insights from our position paper, particularly that the key trait of gray failure is a form of differential observability. We find that in a highly-interactive cloud system, while gray failure is subtle and ambiguous by itself, the "requesters" in the system often observe the failure symptoms. We build a tool, Panorama, that uses program analysis and AOP instrumentation to systematically place observability hooks in a system component, which will report gray failure in other components at runtime.
We write a paper that describes this solution and evaluation results. This paper is published at OSDI 2018.
Modeling and defining gray failures

Cloud scale provides the vast resources necessary to replace failed components, but this is useful only if those failures can be detected. For this reason, the major availability breakdowns and performance anomalies we see in cloud environments tend to be caused by subtle underlying faults, i.e., gray failure. In this work, we present real-world gray failure examples to understand their characteristics and the risks they pose to cloud systems. Drawing from these data points, we make the first attempt to characterize gray failure with a generic model. We find that the key trait of gray failure is a form of differential observability.
We write a position paper to advocate the importance of gray failure problem and describe our model. This paper is published at HotOS 2017.
Defensive and utilitarian mobile operating systems
Lease-based, utilitarian resource management

Existing OS-level solutions to the mobile app energy misbehavior problem is either libertarian, which allows apps to hold resources until they are explicitly released, or authoritarian, which monitors resource usages and throttles excessive usage. While the authoritarian approach helps reduce energy consumption, it prohibits apps from taking advantage of the resources to do useful work. In this project, we explore a missing design point---a utilitarian approach. We adapt the lease mechanism from distributed systems into a mobile OS resource management abstraction to mitigate app energy bugs and use utility to make informed lease decisions.
Our paper that describes LeaseOS is published at ASPLOS 2019. It won the Best Paper Award.
Defending against immature apps
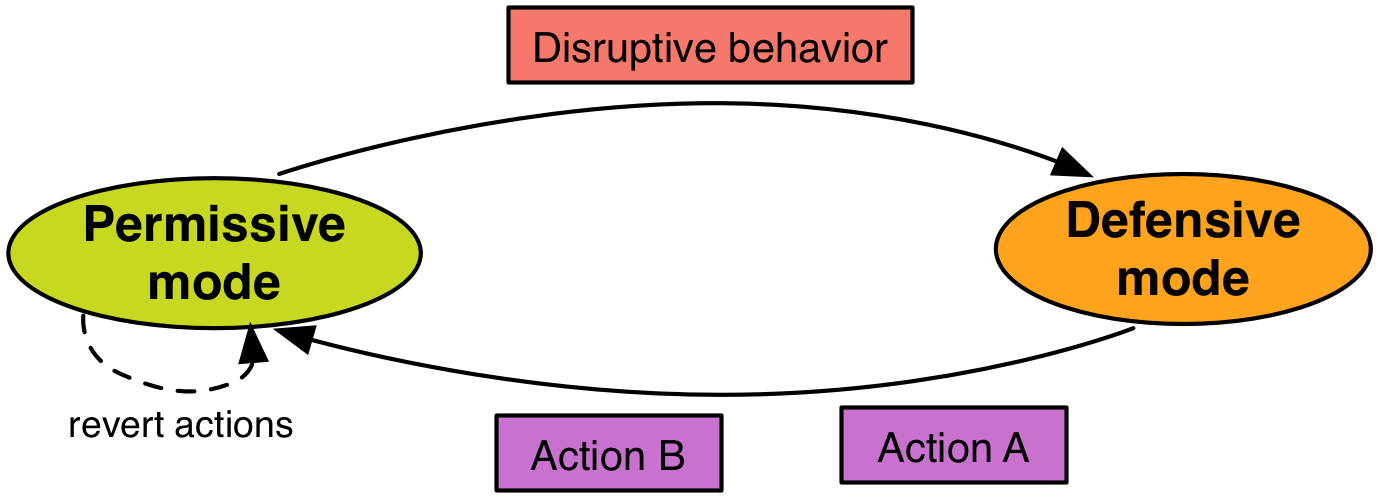
Nowadays there's an app for almost anything. Unfortunately, mobile apps are in general weaker in terms of quality compared to traditional software because of developer inexperiences and limited resources. Many apps, despite having useful features, exhibit immature behaviors, e.g., fast battery drain, agressive updates, excessive cellular data usage, notifications.
In the DefDroid project, we explore OS-level solutions to address the Disruptive App Behavior (DAB). DefDroid is designed to defensively re-act to app misbehavior by taking corrective actions at runtime without compromising app usability.
Our paper that describes DefDroid is published at MobiSys 2016.